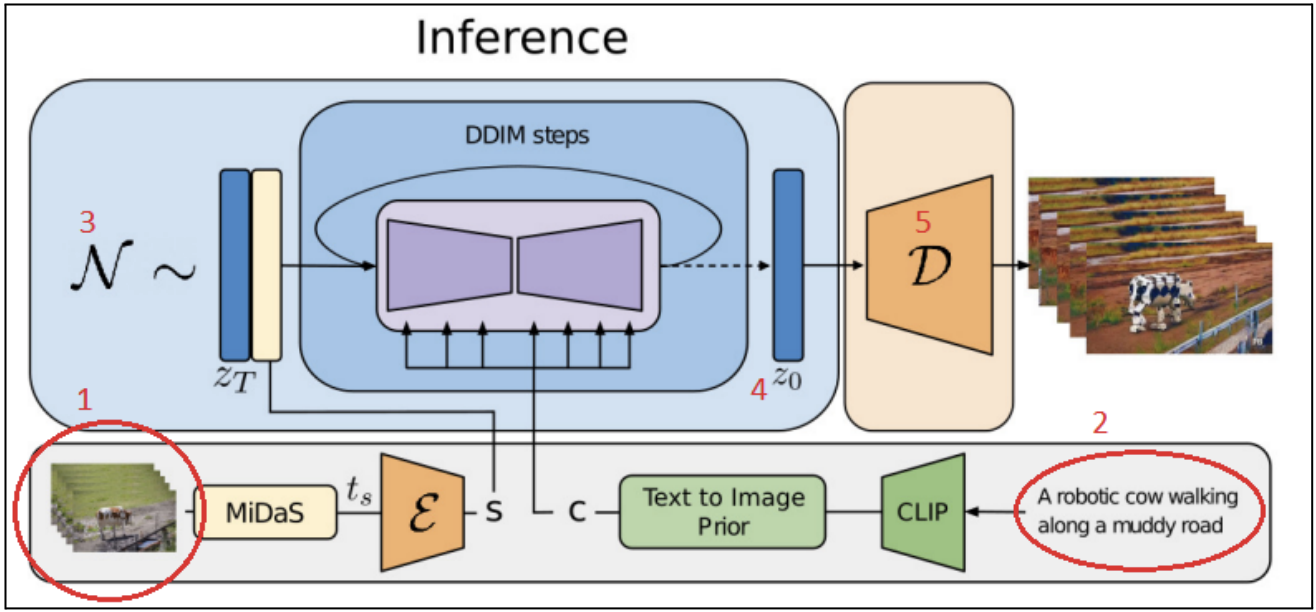
MiDaS











Ce processus est en 5 étapes, les 1 et 2 sont dans le bas de l’image, les 3,4, et 5 dans le haut de l’image. Lorsque l’on fournit à l’IA une vidéo donnée (entouré à gauche, vidéo d’une vache dans un enclos) et un prompt pour la customiser (entouré à droite le texte demandant une vache robot), voici comment le système fonctionne :